Architecting for fault tolerance is hard. One way we mitigate faults is by building automatic redundancies. That is, we architect software in such a way that if a component fails, a backup kicks in to restore functionality so the system as a whole doesn't fail. This could mean maintaining 100% functionality with no noticeable impact or the system could continue to operate in a degraded service mode. In this way we have accepted faults as a fact of life; we understand that the question isn't IF, it’s WHEN.
Software creation has long been compared to building a bridge. Think of the rivets in the Golden Gate Bridge. There are over 1.2 million rivets combined in the two towers. Of those 1.2 million rivets, a lot will fail. Ultimately, they will all fail (hopefully not at the same time) due to their age and the exposure to the environment. In fact, a high percentage of them COULD fail at the same time and the bridge won’t collapse. Just look at all it! That’s real life redundancy. As a side note, when rivets fail they are replaced with high strength steel bolts. Speaking of bolts, the cable bolts must be retightened from time to time because of constant temperature and load changes which cause the bolts to relax. But again, some bolts could fail without losing an entire cable.
What does this have to do with the cloud? A lot, actually. The cloud is all about fault tolerance and redundancy, among other things. We have talked before about AWS and some of its benefits. A couple aspects of AWS to architect for fault tolerance are Auto Scaling and Elastic Load Balancing. Auto Scaling is the idea that provisioning and scaling computing resources should be automatic; that is, with no human intervention, because events like a server going down or a disk going bad shouldn’t be enough to stir someone in the middle of the night. Elastic Load Balancing detects unhealthy instances within its pool of Amazon EC2 instances and automatically reroutes traffic to healthy instances, until the unhealthy instances have been restored. Auto Scaling and Elastic Load Balancing are an ideal combination – Elastic Load Balancing gives you a single DNS name for addressing and Auto Scaling ensures there is always the right number of healthy Amazon EC2 instances to accept requests.
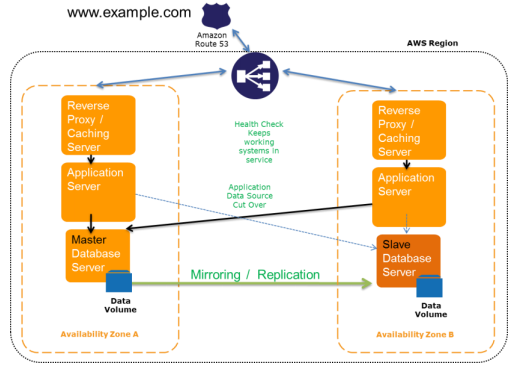
In the cloud, there is also the notion of geographic diversity. We have the ability to stand up instances in one geographic location and have a backup in another geographic location or region. Many corporations and IT groups already have this notion by using a physically separate site called Disaster Recovery or Operations Continuity. Typically, if the primary site is compromised or is adversely affected, some mechanism will utilize the separate site so operations can continue normally or in a degraded service fashion. AWS takes this a step further by providing Availability Zone within a given Region which consists of one or more Availability Zones. These are distinct locations that are designed to be insulated from failures in other Availability Zones but provide for low latency connectivity to other Availability Zones in the same region. In closing, here is a diagram of what a typical AWS deployment might look like in a single Region. To achieve geographic fault tolerance, we would deploy this model across multiple Regions.
{kind=link}